[paper-review] Dream2Real: Zero-Shot 3D Object Rearrangement with Vision-Language Models
NeurIPS-W 2023 Oral. [Paper] [Project Page]
Ivan Kapelyukh1, 2 , Yifei Ren1 , Ignacio Alzugaray2 , Edward Johns1 The Robot Learning Lab at Imperial College London1. The Dyson Robotics Lab at Imperial College London2
Dec. 07
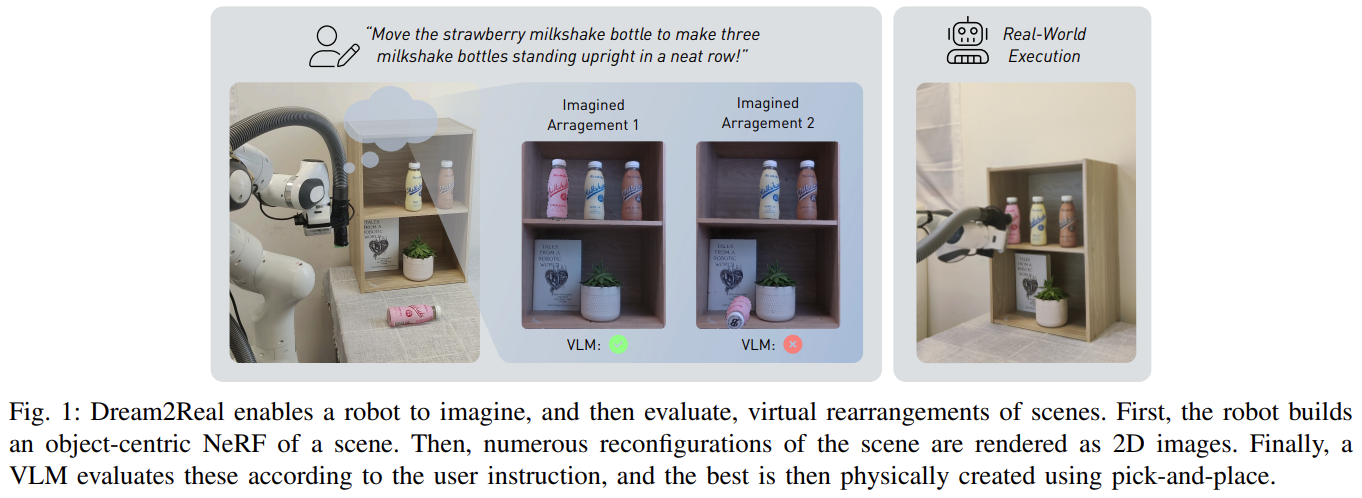
Fig. 1: Overview of Dream-to-Real.
한 문장 요약
- NeRF로 TSDF mesh로 만들어 physics check를 하고, Textual+Visual reasoning으로 best pose를 얻어내자.
Contribution
- 기존의 방법론인 DALEE-E-Bot 과 비교하면 아래의 개선점이 있음.
- DALL-E-Bot can only generate 2D images, so is unsuitable for 6-DoF tasks.
- It is easier to imagine new images by reconfiguring NeRFs, than by learning to generate images.
- Zero-shot Manner로 Robotic rearrangement task를 수행할 수 있다.
- just dreaming and evaluating
- Robot builds an object-centric NeRF of a scene.
- Numerous reconfigurations of the scene are rendered as 2D images.
- CLIP evaluates these according to the user instruction.
- The best is then physically created using pick-and-place.
Methodology:
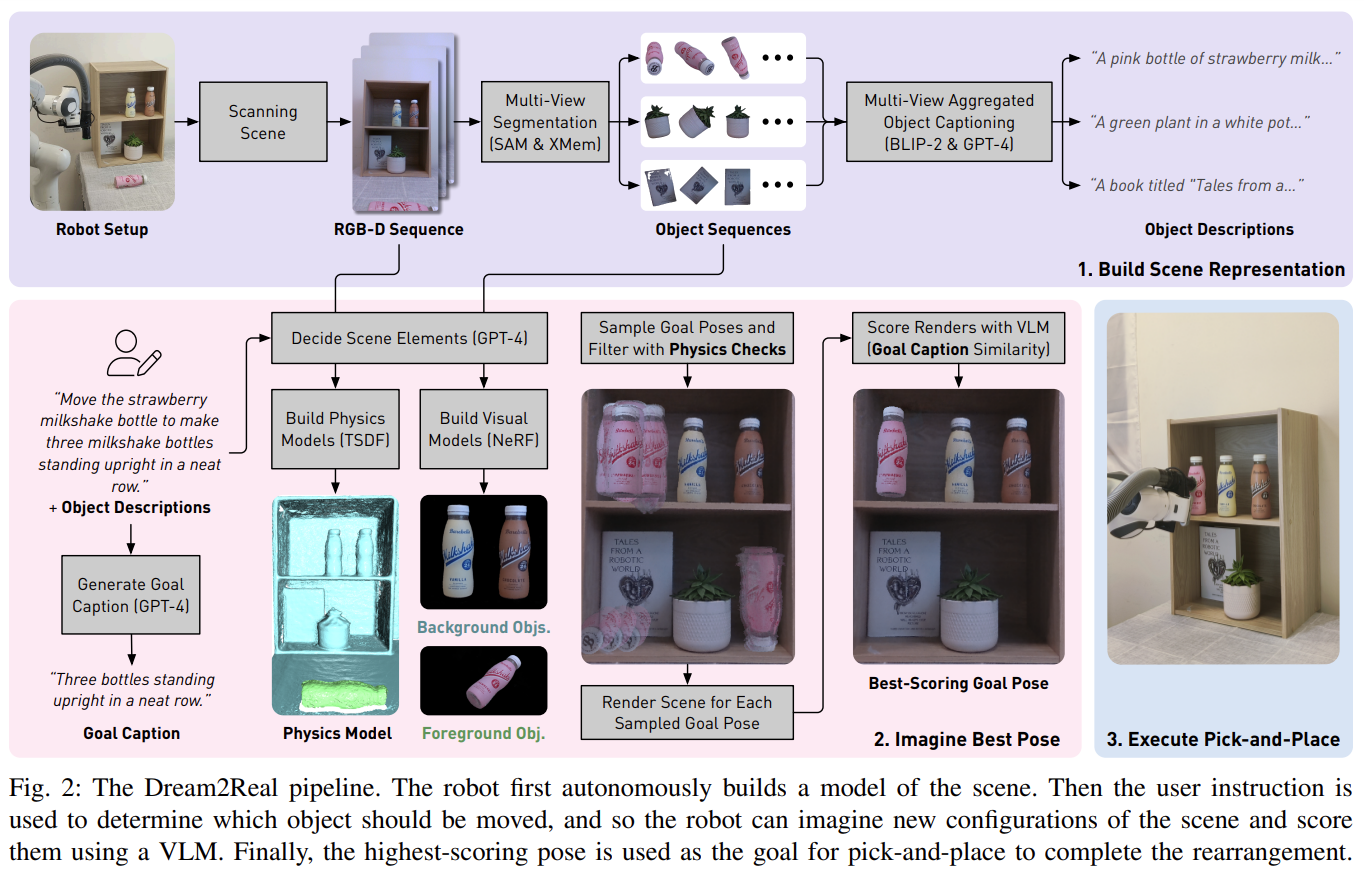
Fig. 2: Framework of Dream-to-Real.
Build Scene Representation
- RGB-D 카메라로 workspace를 반구 형태로 capture: TSDF Format
- Workspace, Target object: NeRF (Instant-NGP)
- [SAM+XMem] Segmentatoin VLMs + BLIP-2
- 해당 모델로 workspace에 대해 semented workspace + target object (background/foreground)를 얻을 수 있다.
- 각 view의 object에 대해 captioning을 BLIP-2 model로 수행함.
Imagine Best Pose
- Workspace에 해당하는 Grid로 샘플링 + Orientation도 discrete set 내에서 샘플링 -> 앞서 생성된 TSDF mesh를 기반으로 physics(collision) check
To build the physics models, we combine depth images from across views to create a separate foreground and background Truncated Signed Distance Function (TSDF) [49], which we find achieves more accurate geometry than extracting a mesh from Instant-NGP.We move (virtually) the movable object’s physics model to each of the sampled poses in turn and check for physical validity, i.e. the object must not be in collision with the scene or unsupported in free space.
- GPT-4 Input: [movable object, relevant objects, the goal caption and the normalising caption]
- movable object: 직접 움직이게 될 물체를 의미합니다.
- relevant object: task의 수행 여부를 판단하기 위해 관측해야 하는 object or region을 의미합니다.
- goal caption: description of the desired final state after the instruction has been fulfilled.
- normalising caption: spatial relationship을 잘 포착하게끔 해주는 목적이라고 합니다. (
description of the scene that remains neutral to the pose of the object being moved.)
Execute Pick-and-Place
Execute Robot action in real-world
Experiments

Fig. 3: Enviroments of Dream2Real.
- Setup; 3개의 서로 다른 real-world scene + 10개의 rearrangement task
- Evaluation metric; Measure task success using success regions.
- H/W; Franka + D435i
Baselines
- DALL-E-Bot
- D2R-One-View, Only use one view: which uses only the first camera view throughout the whole pipeline (including object captioning), avoiding the need for data collection.
- D2R-Distract: do not use GPT-4 (distractor)
- Physics-Only: do not use CLIP to evaluate poses
- D2R-No-Norm: no normalizing captions
- D2R-Vis-Prior
- D2R-NoSmooth: ablates spatial smoothing
Results
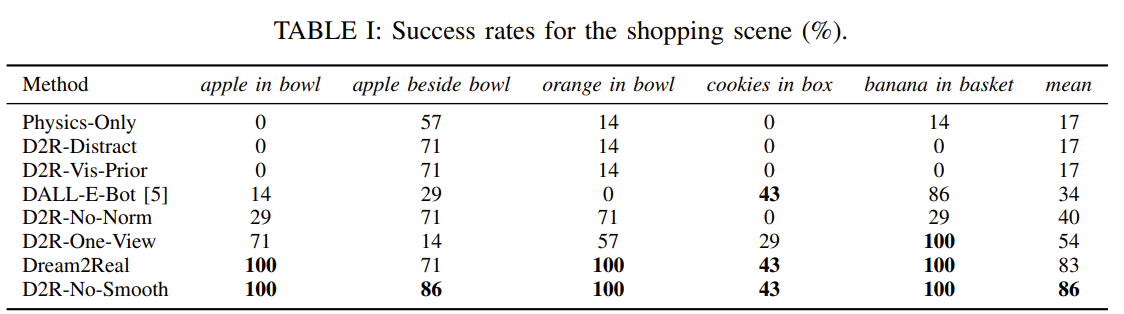
Fig. 4: Table about Shopping Env.

Fig. 4.1: Qualitative results from Shopping Env.
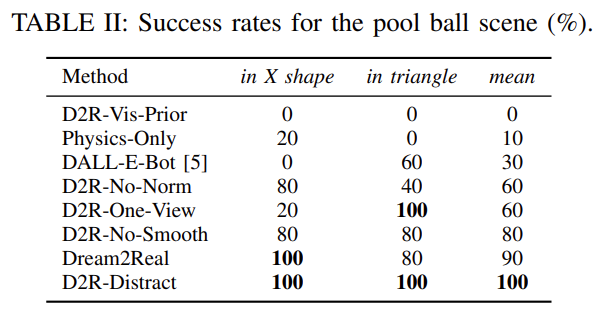
Fig. 5: Table about Pool Ball Env.

Fig. 5.1: Qualitative results from Pool-Ball Env.
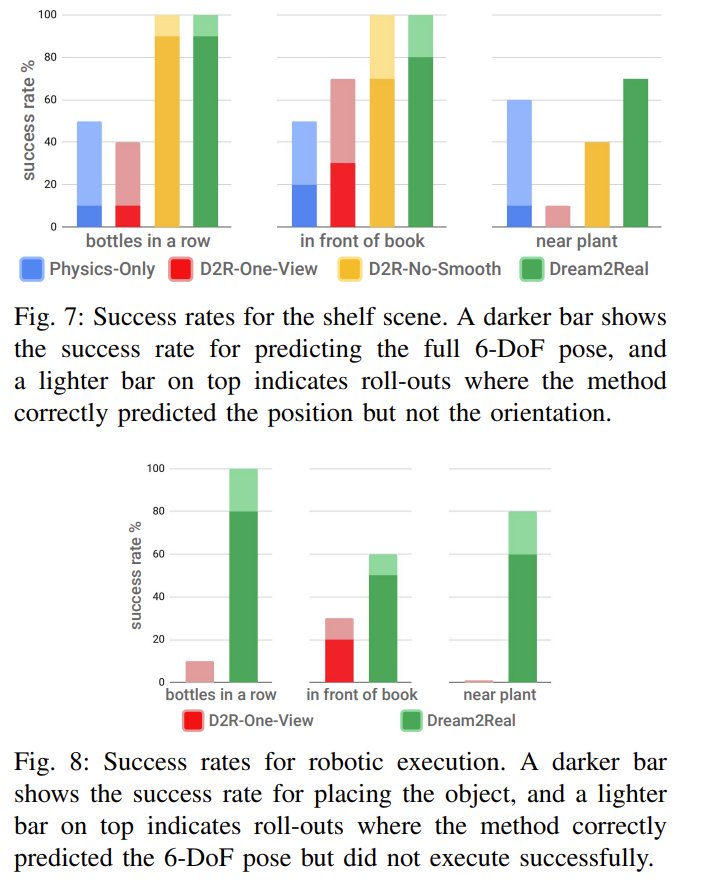
Fig. 6: Success Rate plot for baselines.
Visualize heat map
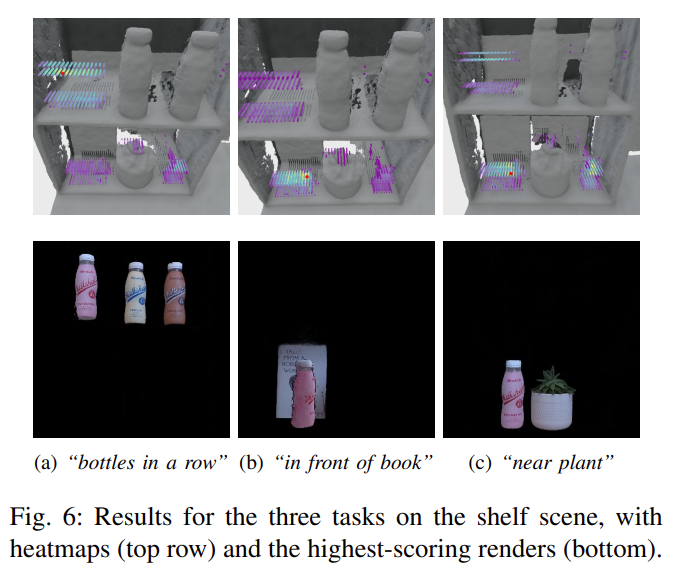
Fig. 7: Visualize renderings from Dream2Real.
Conclusion & Limitation
-
Conclusion
- 저자는 zero-shot manner로 2D VLMs로 3D object rearrangement task를 수행할 수 있는 점을 큰 contribution으로 삼습니다.
- 추후 연구로는 iterative하게 score를 refine하는 방식도 될 수 있을 것이며, multistage-task에 대해서도 수행할 수 있을 것입니다.
-
Limitation
- 하나의 scene을 NeRF로 reconstruct 하는 것에 3~5분 정도 소요된다고 합니다.
- orientation을 discrete set에서 샘플하여, orientation이 더욱 복잡한 task에는 적용하기 어렵다고 합니다. (sampling high-resolution -> high computation cost)
- CLIP에서 bag-of words behaviour의 현상이 일어납니다. 이는 Text에서 단어의 순서가 중요한 경우 입니다.
- e.g.
“a fork to the left of a knife” often places the knife to the left of the fork instead."
- e.g.
Thoughts:
- spots 논문의 컨셉과 유사한 것 같아 읽었습니다. 해당 논문에서는 NeRF로 전체 workspace와 target object를 복원하고, target object의 orientation도 고려해가며 physics check를 합니다.
- 다만 NeRF 기반의 방식이라 하나의 씬에 3~5분 정도 걸린다는 한계가 있다고 저자가 밝힙니다. real-to-sim 측면을 조금 강조하려면 해당 연구에서 한 방식대로 3d mesh를 만들어 내는 것이 좋을 것 같습니다.
- 그리고 해당 논문에서는 score heatmap을 정의해 physics-check + similarity check를 통해 best-pose 하나만을 찾습니다. CLIP으로 이미지와 desired goal-pose(caption) 간의 similarity로 best pose를 찾습니다.
- 여기서 goal-caption은 object pose에 대한 내용만을 이루며, 저희가 spots에서 수행했던 semantic reasoning과는 다르다고 느꼈습니다.
- spots 논문에 이어서, physics check를 여러 robot action에 대해서 수행하는 방향으로 확장하면 재밌을 것 같습니다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: