[paper-review] User preference optimization for control of ankle exoskeletons using sample efficient active learning
Science Robotics 2023. [Paper] [Code]
Ung Hee Lee and Varun S. Shetty and Patrick W. Franks and Jie Tan and Georgios Evangelopoulos and Sehoon Ha and Elliott J. Rouse
18 Oct 2023
한 문장 요약
요약: Exoskeleton에서 Preference를 결정짓는 control parameter를(=4개) 자동으로 튜닝해주는 연구를 수행했다.
Offline RL method that never needs to evaluate actions outside of the dataset, but still enables the learned policy to improve substantially over the best behavior in the data through generalization
Keyword: Preference-Based Learning, Exoskeletons
Abstract
- 기존의 한계
- resource intensive
- only enabling a single objective optimization
- we can do it for many factors, including comfort, fatigue, and stability, among others
- conveniently tune the four parameters
- Approach
- used an evolutionary algorithm to recommend potential parameters, which were ranked by a neural network
RankNet.- real-time feedback as a force-choice comparison (=binary comparison)
- accuracy of 88% on average when compared with randomly generated parameters.
- user-preferred settings stabilized in 43 \(\pm\) 7 queries.
- used an evolutionary algorithm to recommend potential parameters, which were ranked by a neural network
Introduction
기존의 웨어러블 기기에서 수행된 PBL은 두 가지 방식이 있다.
- Expert-based tuning to mimic natural human locomotion ⇒ Learning from Demonstration
- Automatic tuning based on metabolic rate or other physiological objectives.
- 위 방법들은 성공적으로 수행되어 왔지만, 오직 하나의 요소에 대해서만 PBL이 수행되어 왔다. (=
single objective) - 따라서 이러한 한계를 해결하고자 여러 요소를 고려하는
Multi-objectiveoptimization 방법들도 연구되고 있지만, 아직까진 그렇게 성공적이진 않다고 한다.
- 위 방법들은 성공적으로 수행되어 왔지만, 오직 하나의 요소에 대해서만 PBL이 수행되어 왔다. (=
- low-dimensional controller parameter space(=튜닝 파라미터의 총 갯수)로는 실제 환경의 모든 상황으로 확장이 불가하며, 저자는 이를 active learning으로 수행하겠다고 한다.
- The algorithm searches a parameter space automatic
요약하자면, 저자가 주장하는 contribution은 아래의 두 가지 입니다.
- sample-efficient optimization algorithm: four-dimensional parameter space
- real-time framework for allowing users to determine preference at will
-
RankCMA-ES라는 이름으로 알고리즘을 제안함.
-
Contribution
- Sample-Efficient
- 이전 연구에서 Covariance Matrix Adaptation-Evolutionary Strategy (CMA-ES)로 metabolic rate를 최적화 하는 연구가 수행되었으나 PBL로는 확장되지 못하였음.
- 저자는 RankNet을 사용해 CMA-ES 방법론을 합침. (Binary comparison: [A or B])
- 이전 PBL 연구에서는 5개의 option에 대해 2개의
- Real-world에서 사용 가능하다
- 웨어러블 기기와 사용자의 binary comparison만 있으면 내부 알고리즘이 동작하므로 실생활에 사용할 수 있다는 의미.
- 그리고 사용자가 tuning pace를 조절할 수도 있음.
Approach
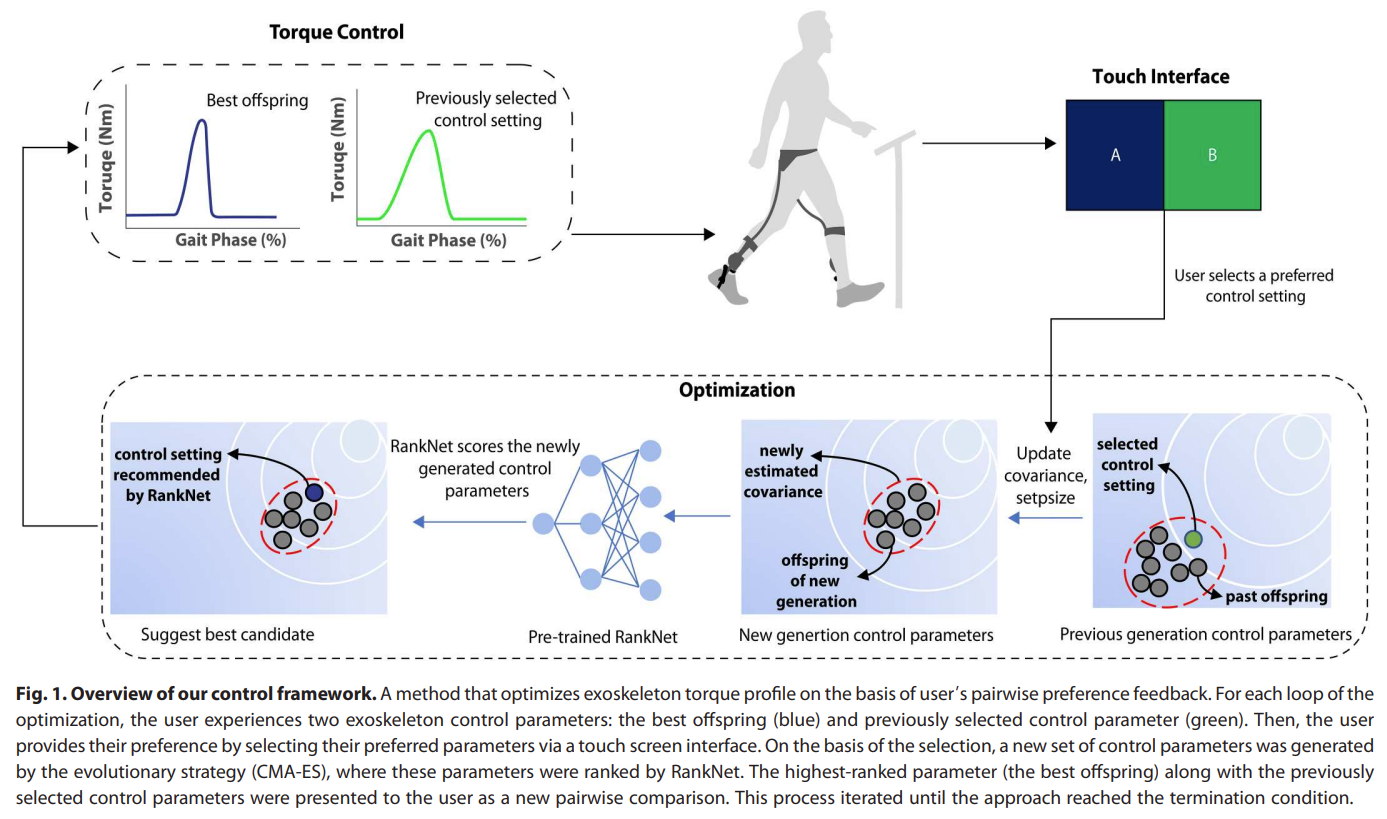
Fig. 1: Overview of the Exoskeleton PBL.
- 저자는 RankNet을 사용하여 preference를 모델링 했다. (preference score를 continuous하게 추정하기 위해 preference가 neural network에서 활용된 연구임.)
- Input: controller setting / output: normalized in a [0~1] score (latent user score)
- Two-Dim. controller parameter에서 perference model을 pre-train 한 후에 Four-Dim.에서 optimization을 수행한다. (pre-train 과정에선 이전 연구(Human-in-the-loop optimization of exoskeleton assistance during walking)에서 수행된 데이터를 사용한다고 함.) - Controller parameter: peak torque and peak torque timing

Fig. 2: Pseudo Algorithm of the Exoskeleton PBL.
- Optimization part
- user-independent preference model: RankNet
- pre-train을 위해 이전 연구에서 사용된 데이터셋을 활용함.
- 12명의 참가자 + 3개의 다른 속도 (1, 1.2, and 1.4 m/s)
- 데이터로부터 mean과 covariance를 얻어내서, 12개의 개별적인 2D gaussian function을 취득함. ⇒ 이를 preference score로 사용함.
- pre-train을 위해 이전 연구에서 사용된 데이터셋을 활용함.
- user-dependent preference model (black-box optimizer): CMA-ES
- multivariate normal distribution에서 샘플을 추출
- 이전의 것과 비교하여 더 선호하는 것을 선택
- 선택된 것을 기반으로 covariance matrix \(C\), step size \(\sigma\) 를 업데이트 하며 distribution이 바뀜.
- 저자는 \(1+\lambda\) CMA-ES 방법론을 사용함.
- 이는 suboptimal에 취약하지만, 빠른 수렴성을 보여서 사용한다고 함.
- 1: parent의 수
- +: new generation이 children/parent pool에서 선택된다는 의미
- \(\lambda\): offspring의 수, search space를 결정함, scheduling parameter
- user-independent preference model: RankNet
Experiments
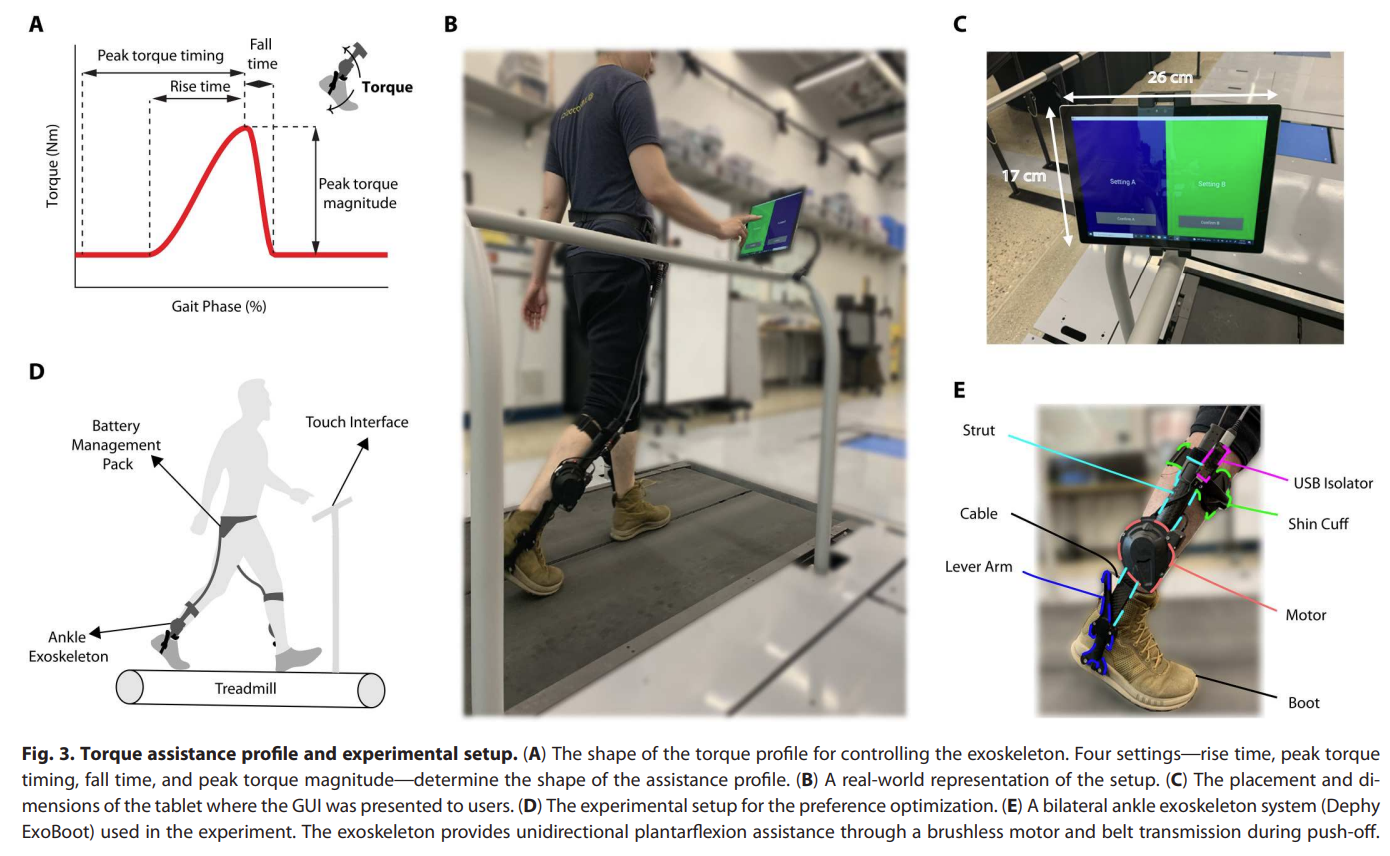
Fig. 3: Experimental Setup of the Exoskeleton PBL.
- 실험 세팅
- 피실험자는 총 14명이며 참가자 당 5번의 실험을 수행한다.
- 피실험자는 트레드밀에 고정된 속도 1.2 m/s로 걸으며 2개의 option A/B 를 선택할 수 있는 터치 스크린이 있었으며, 자유롭게 A/B option을 체험해볼 수 있었음. 이 중에서 어떠한 것이 더 좋은지 선택하게끔 함.
- 이러한 과정을 50번 정도 수행함. 이 숫자는 선행 연구에 기반을 두었다고 언급함.
- 이렇게 main(optimization+validation) session은 39 \(\pm\) 18 분 소요되었음.
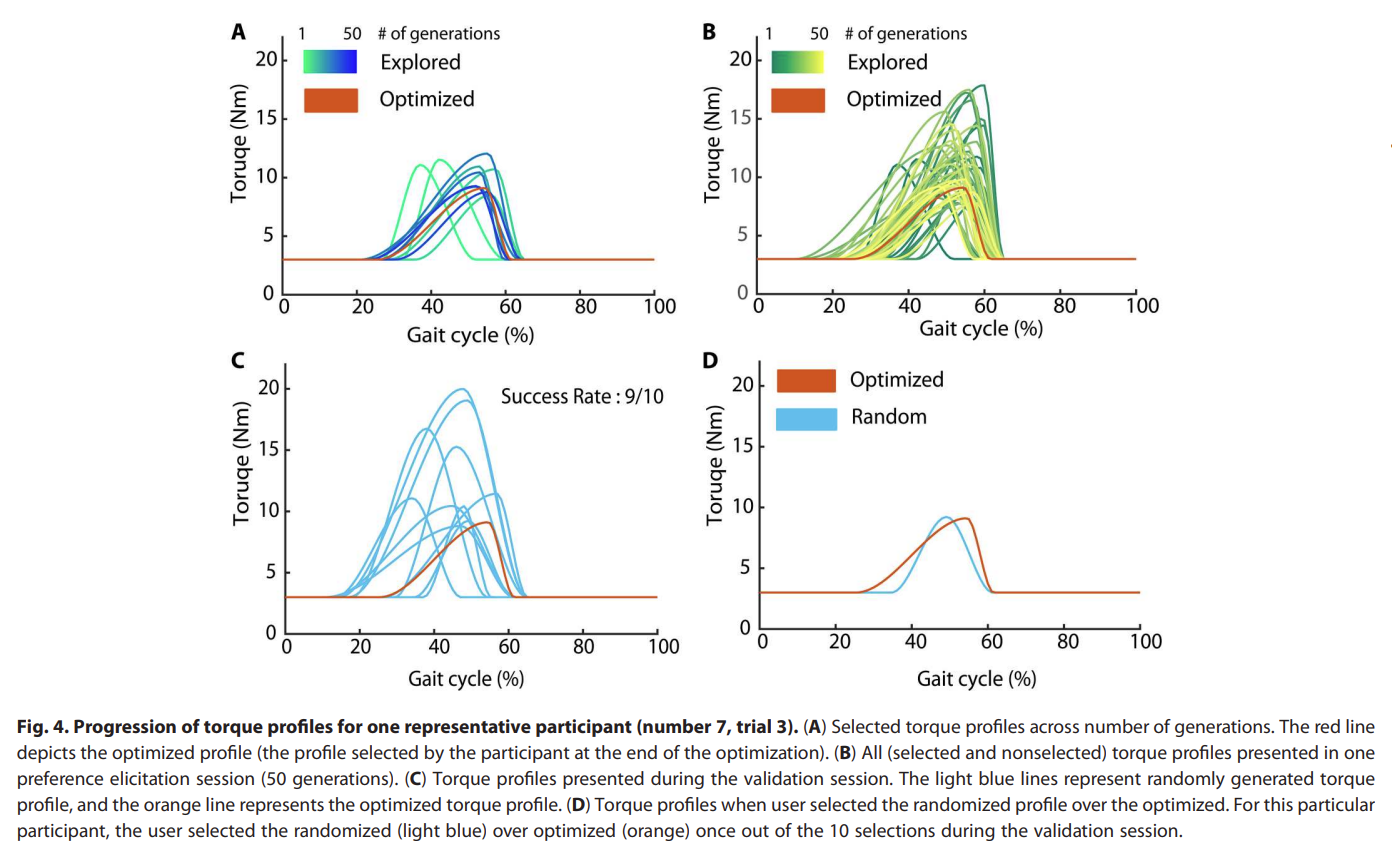
Fig. 4: Gait result of the Exoskeleton PBL.
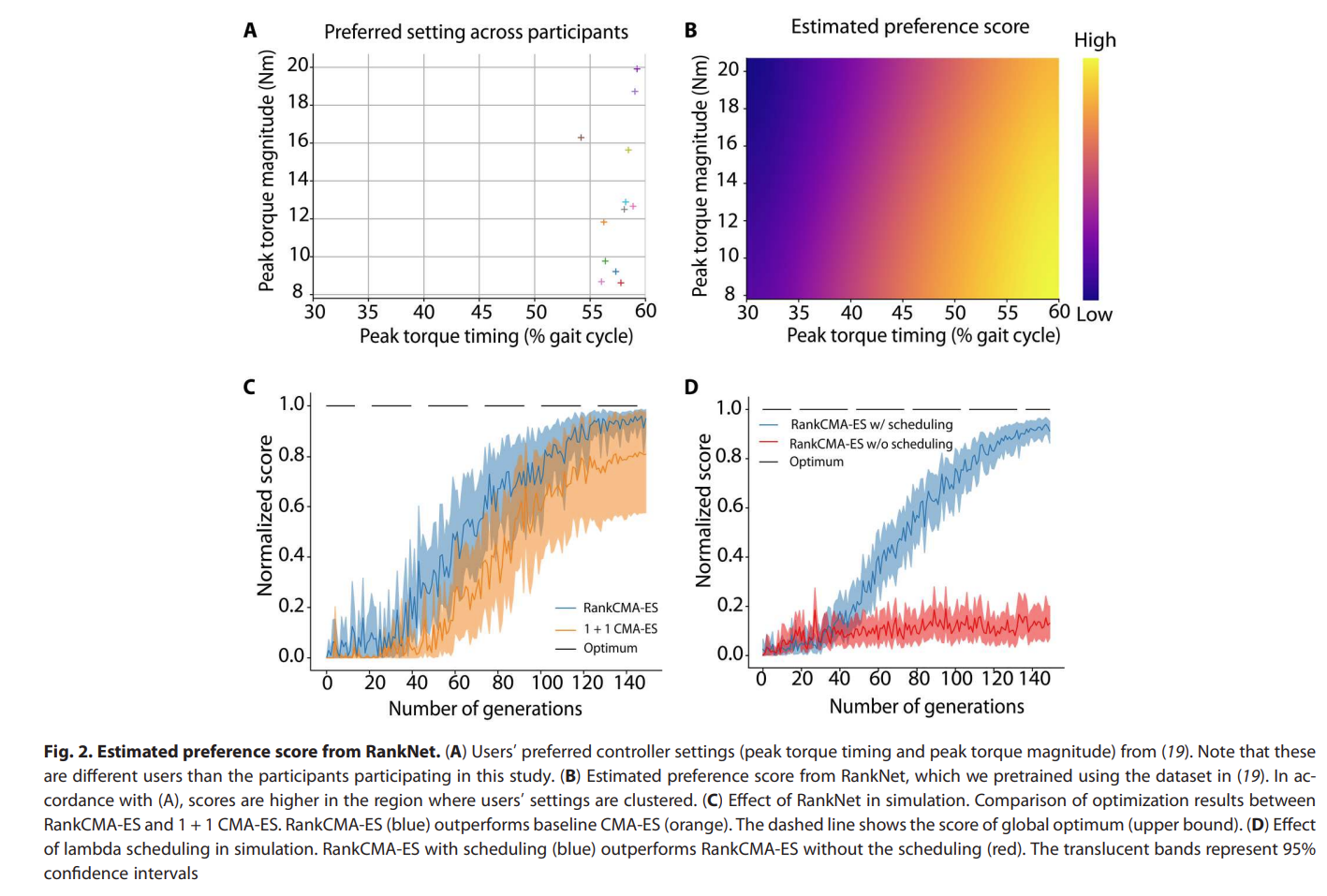
Fig. 5: RankNet result.
- RankCMA-ES를 leave-one-subject-out cross validation으로 수행했다고 함.
- n개의 데이터에서 1개를 Test Set으로 정하고 나머지 n-1개의 데이터로 모델링을 하는 방법
- CMA-ES 를 baseline으로 삼음.
- RankCMA-ES가 더 적은 수(=30 회)의 generation으로 GT에 근접한 score로 수렴했고, baseline은 150회의 generation으로 sub-optimal로 수렴했다. ⇒ sample-efficiency
Thought
- Introduction에서 밝히길 본 연구는 partial-assist system에 대해서 PBL을 수행했다고 하며, 기존의 연구는 complete-assist exoskeleton에서 PBL이 수행되어 왔다고 합니다. (Bayesian-Optimization + Gaussian Process를 활용함.)
- 아마도 이 이유 때문에 Baseline을 pbl이 아닌 CMA 으로만 수행한 것 같습니다. (PBL에 대해서 수행하는 논문이지만 baseline에는 PBL 관련된 것이 없어서 처음에는 조금 의아했었습니다.)
- 해당 논문에서 사용된 factor로는 다음의 4개를 활용했습니다. rise time (r_t), peak torque timing (p_t), fall time (f_t ), and peak torque magnitude.
- 저자도 논문에서 밝히길 더 많은 수의 factor를 정의해 문제를 해결할 수는 있다고 하며, text로 표현된 내용에 기반해서 preference를 추정하는 접근도 해볼 수 있지 않을까 라는 생각을 했습니다.
- 추가로, preference model에 대해서도 RankNet 이외에도 다른 ranking method를 활용해볼 수 있을 것 같습니다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: