[paper-review] Motion Planning Networks
Ahmed H. Qureshi, Anthony Simeonov, Mayur J. Bency and Michael C. Yip 1 University of California San Diego, La Jolla, CA 92093 USA1
Feb. 24

Fig. 1: Introduction figure about MPNet paper.
한 문장 요약
Learnable한 Collision-free Motion Planning Network를 제시한다.
Contribution
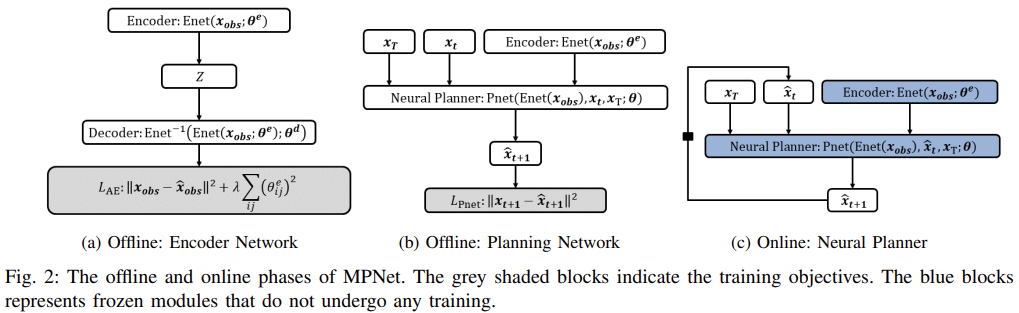
Fig. 2: Overall architecture about MPNet.
- Offline: 1) Encoder Netowork, 2) Planning Network
- Online: Neural Planner
Terminology:
- \(Q\): ordered list of length \(N \in \mathbb{N}\)
- \(\{q_{i}=Q(i)\}_{i\in N}\): mapping from \(i\in \mathbb{N}\) to the \(i\)-th element of \(Q\).
- \(X \subset \mathbb{R}^{d}\): state space, where \(d\in \mathbb{N}\) is the dimensionality of the state space.
- \(d_{w}\in \mathbb{N}\): workspace dimensionality
- \(X_{\text{obs}} \subset X\): obstacle state space
- \(X_{\text{free}} \subset X\textbackslash X_{\text{obs}}\): obstacle state space
- Initial state \(x_{\text{init}} \in X_{\text{free}}\), goal region be \(X_{\text{goal}} \subset X_{\text{free}}\)
목적은 solution path \(\tau\)가 entirely obstacle-free space \(X_{\text{free}}\)에 존재하도록 하는 것이다.
Methodology:
(A) offline training of the neural models, and (B) online path generation; 2개의 모듈로 구성되어 있다.

Fig. 3: Algorithm about MPNet (Offline).
- Offline Training
- Obstacle point cloud(=scene)을 latent space에 embedding 시키고 (Encoder Network), obstacle encoding \(Z\)로부터 Planning Network로 \(\hat{x}_{t+1}\)을 추정한다.
- Enet: Encoder Network
- Contractive Autoencoder를 사용했다.
- obstacle pointcloud \(X_{\text{obs}}\)를 \(Z\in \mathbb{R}^m\)에 embedding 시킴.
- Contractive Autoencoder를 사용했다.
- \(\theta^{e}\): parameters of encoder
-
\(\theta^{d}\): parameters of decoder
- Pnet: Planning Network
- \[\hat{x}_{t+1}=\text{Pnet}((x_{t},x_{T},\mathbf{Z});\mathbf{\theta})\]
- Expert data로 학습을 진행함. (MSE Loss)

Fig. 4: Algorithm about MPNet (Neural Planner).

Fig. 5: Algorithm about MPNet (Replanning).
- Online Path Planning
- Offline에서 학습한 모델을 기반으로 (collision-free) motion planning을 수행하기 위해 Bidirectional path generation heuristic을 제시함.
- Pnet: stochaticity를 추가하기 위해 일정 확률로 dropout 을 수행함. (\(p: [0.1]\in \mathbb{R}\))
- Lazy States Contraction (LSC): connect_tree 함수와 동일함.
- Steering: 일반적인 planner의 steer 함수와 동일함.
- isFeasible: 일반적인 planner의 feasibility 함수와 동일함.
- Neural Planner: 저자가 말하는 Bidirectional path generation.
- \(\tau^{a}, \tau^{b}\): 각각 init state로부터 시작하는 path, goal state로부터 시작하는 path를 의미함.
- 우선 \(\tau^{a}\)부터 범위를 확장해가며, planning을 수행함. 여기서 not connectable 한다면 \(\tau^{b}\)부터 범위를 확장해감: swap function
- Offline에서 학습한 모델을 기반으로 (collision-free) motion planning을 수행하기 위해 Bidirectional path generation heuristic을 제시함.
Implementation & Experiments
- 110개의 서로 다른 workspace: simple 2D, rigid-body, complex 2D/3D
- 100개의 workspace, 각 4000개의 trajectory로 학습을 수행함. 여기서 사용된 trajectory는 RRT\(^*\)로부터 취득함.
- Enet: three linerar layers and an output layer, Parametric ReLU를 사용함.
-
Pnet: 9-layers and 12-layers DNN, PReLU를 사용함. 모든 은닉층에 dropout도 포함되어 있음.
- Baeslines: MPNet+Neural-Replanning / MPNet+Hybrid-Replanning / Informed-RRT\(^*\) / BIT\(^*\)
- Evaluation metric: Time [s] / Accuracy [%]
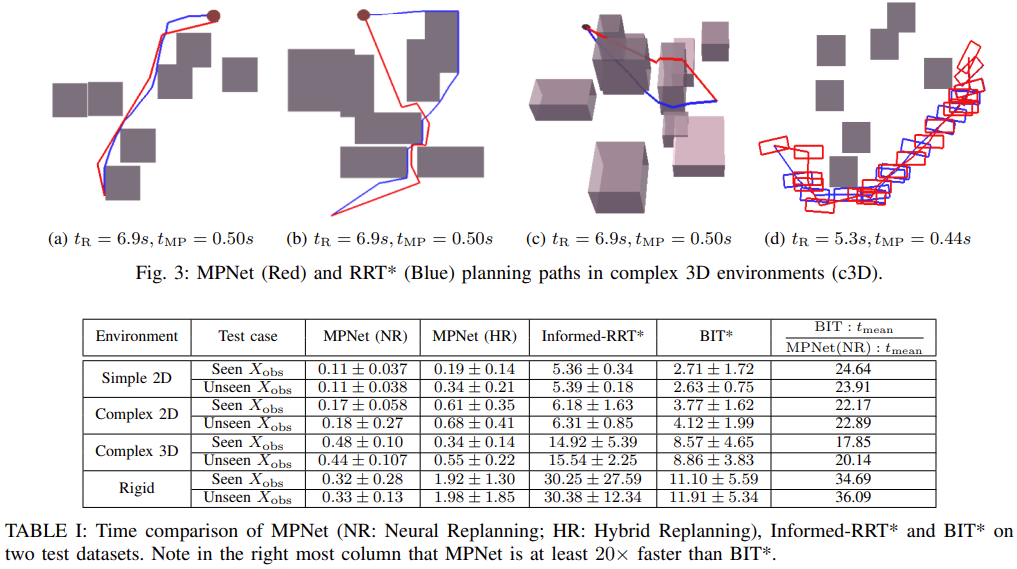
Fig. 6: Results about MPNet.
Conclusion:
MPNet은 (1) obstacle geometry에 관계없이 motion planning을 잘 하며, (2) exec. time이 평균적으로 1초 이내에 수행되었으며, (3) unseen obstacle location에서도 잘 동작했으며, (4) completeness를 보장한다.
Thoughts:
- Encoder에 Scene pointcloud가 들어가며, Contractive Autoencoder로 obstacle에 대해 embedding 시킨다는 점에서 제가 진행하고자 하는 연구와 유사한 점을 느꼈습니다.
- 다만 단순한 Linear layer(PReLU) 만으로 pointcloud 데이터를 학습했다는 것이 신기합니다. 해당 시기에 PointNet/FoldingNet/DGCNN 등 pointcloud based architecture가 여러 있었는데도 불구하고 이렇게 수행했다는 것이 신기합니다. 제가 알기로는 rigid motion에 대해 invariant 해야할텐데, 이를 단순 linear layer 만으로 어떻게 잘 학습했는지가 궁금합니다.
- 앞서 학습된 Autoencoder를 사용해, expert trajectory로 planner를 학습합니다.
- 알고리즘상으로는 RRT-Star와 큰 차이는 없으며, Bidirectional하게 수행된다는 것이 차이점이라고 생각됩니다.
- 논문에서는 Obstacle pointcloud가 입력으로 들어간다고 밝히지만, 정확히 어떠한 형식으로 사용되는지는 설명이 조금 부족하다고 느껴집니다.
- CAE 모델에 대해서 간단하게 MNIST로 코드를 수행해봤었는데, Point cloud data로도 학습이 잘 수행되는지 확인해봐야 할 것 같습니다.
Enjoy Reading This Article?
Here are some more articles you might like to read next: