[paper-review] MOKA: Open-Vocabulary Robotic Manipulation through Mark-Based Visual Prompting
ArXiv, 2024. [Paper] [Project]
Kuan Fang_, Fangchen Liu_, Pieter Abbeel, Sergey Levine
- denotes equal contribution, alphabetical order Berkeley AI Research, UC Berkeley
Mar. 05.
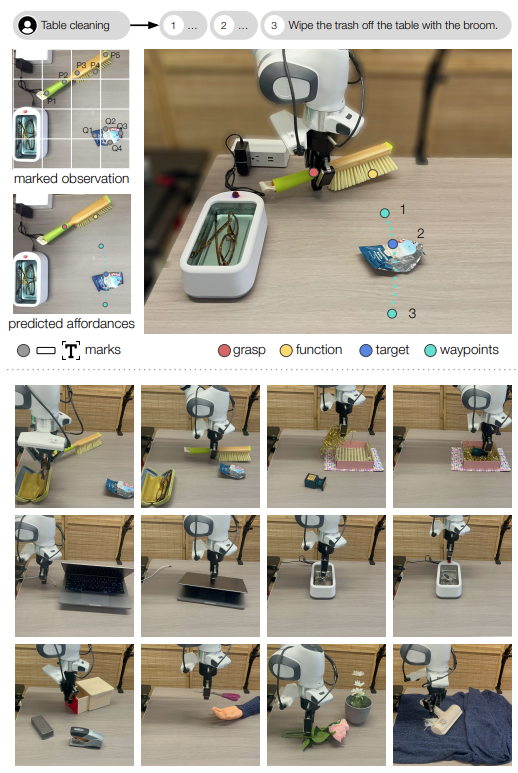
Fig. 1: Overview of MOKA.
Title
MOKA: Open-Vocabulary Robotic Manipulation through Mark-Based Visual Prompting (ArXiv, 2024)
Summary
MOKA converts the motion generation problem into a series of visual question-answering problems that the VLM can solve.
Method
- They introduce a point-based affordance representation that bridges the VLM’s prediction on RGB images and the robot’s motion in the physical world
- They refer to the physical interaction at each stage as a subtask, which includes interactions with objects in hand (e.g., lifting up an object, opening an drawer), interactions with environmental objects unattached to the robot (e.g., pushing an obstacle, pressing a button), and tool use which involves grasping a tool object to make contact with another object.
- Decompose the task into a sequence of feasible subtasks based on the free-form language description ( l )
- Then use VLM (GroundedSAM) to segment objects from the 2D image and overlay them (similar approach to SoM). Additionally, for each of the subtasks, the VLM is asked to provide the summary of the subtask instruction.
Thoughts
- This paper’s approach is similar idea with the previous approach of VPI paper. I read this paper with great interest.
- They have to lift all points from the 2D image into the 6D Cartesian space. So they only consider the cases where the waypoints are at the same height as the target point in most common table manipulation scenarios.
- This point would limit the scope of this paper.
- Since robust grasping relies on contact physics, they do not rely directly on the predicted grasp pose from the VLM, but use a grasp sampler that is closest to the response grasp pose.
Enjoy Reading This Article?
Here are some more articles you might like to read next: