[paper-review] Shelving, Stacking, Hanging: Relational Pose Diffusion for Multi-modal Rearrangement
Anthony Simeonov, Ankit Goyal_, Lucas Manuelli_, Lin Yen-Chen, Alina Sarmiento, Alberto Rodriguez, Pulkit Agrawal__, Dieter Fox__ Massachusetts Institute of Technology, NVIDIA Research, Improbable AI Lab
Jul. 10.
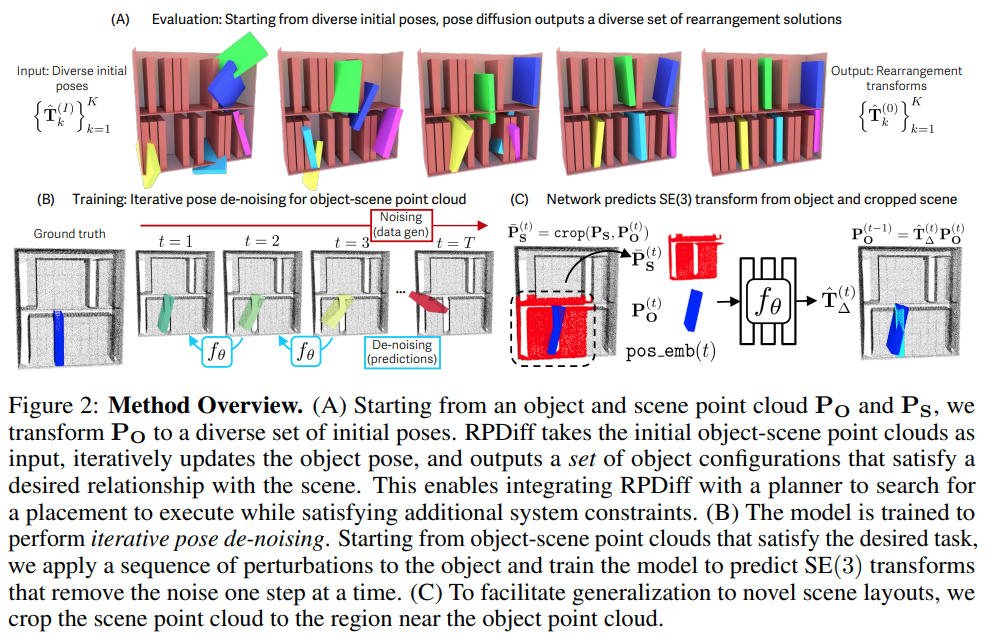
Fig. 1: Overview of RPDiff Architecture.
Title
Shelving, Stacking, Hanging: Relational Pose Diffusion for Multi-modal Rearrangement (CoRL, 2023)
Summary
Solving placement task in complex environment via diffusion-process.
Method
- Iteratively de-noise the 6-DoF pose of the object until it satisfies the desired geometric relationship with the scene point cloud.
- Train a neural network (f_{\theta}) to predict an SE(3) transformation from the combined object-scene point cloud at each time step (t).
- They also using separate clasifier (h_{\phi}) to avoid “local optimal” solutions by scoring the predicted poses among 0~1.
- They use transformer for processing point clouds and making pose predictions: 1) identify important geometric parts within the object and the scene, 2) capture relationships that occur between the important parts of the object and the scene.
Thoughts
- The paper’s idea is intuitive. They consider (the position and the orientation) of target object and I think it is better than the other real-to-sim approaches.
- It seems like the paper of “6-dof graspnet” in the context of placement task because this paper consider the value of placement score among 0~1.
- But the author says that the limitation is “demonstration” data can only be easily obtained via scripted policies in simulation.
- And I think one more limitation is that they execute the predicted placement in open-loop. Adding the module about reacting or recovering from disturbance would be better.
Enjoy Reading This Article?
Here are some more articles you might like to read next: